이번에 해볼 내용은 출생자 수 와 합계출산율 데이터를 이용해 그래프를 만들어 볼 예정이다.
해당 데이터는 e-나라지표 사이트에서 받아올 수 있다.


받아온 파일을 열어서 확인해보면, 실제 데이터가 들어있는 위치는 3행~5행이며, A열:K열 까지 데이터가 저장되어 있다.

이제 pandas 라이브러리를 통해 해당 엑셀파일을 불러오면 된다.
skprows=2 : 위에서부터 2행은 건너뛴다.
nrows=2 : 제목이 될 column을 제외한 2행을 가져온다. (즉 총 3행의 데이터를 가져온다)
index는 column[0]이 된다.
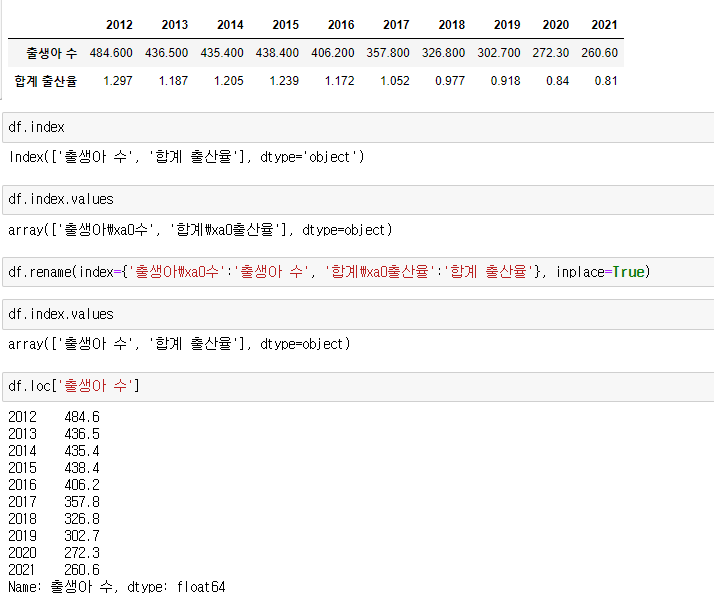
가져온 데이터를 사용하려 하는데, 하나의 문제가 생겼다.
index.values를 통해 해당 index 값들에서 특수문자가 들어가 있음을 발견했다.
rename을 통해 해당 index의 이름을 다시 변경해 주고, 사용하면 된다.

만약 해당 작업이 번거롭다면, iloc[]을 이용해 정수형으로 값을 불러와서 사용하면 된다.

행과 열 데이터 위치를 바꾸는 가장 간단한 방법은 바로 pandas 에서 제공하는 T 라는 예약어를 사용하는 것이다.
이렇게 바뀐 데이터를 다시 df라는 변수에 할당해 주고, 이제 본격적으로 그래프를 그려볼 시간이다.

그래프에 보다시피 굉장히 심각한 문제가 생겼다.
바로 합계 출산율의 경우 그 값의 범위가 0.8~1.3 사이의 값이기 때문에, 출생아 수 와 y축을 공유하기에는 결과값의 차이가 너무 심하다.

plt.subplots()를 통해 다중 그래프를 그려주게 되는데, 이때 전달값은 비워두게 되면 단 하나의 그래프만 그릴 수 있다.
ax1 에는 처음대로 출생아 수 그래프를 그려준다
ax2라는 새로운 변수에 ax1.twinx()라는 값을 설정해 주는데, 이는 twin x축 즉 x축을 같이 사용한다는 뜻이다.
그래프를 보면 좌측에는 출생아 수 의 y축 값이, 우측에는 합계 출산율의 y축 값이 보인다.

출생아 수 그래프는 bar 형태로 변경해 주었다.
이제 각 y축을 설정해 주면, 1차 가공은 완료이다.
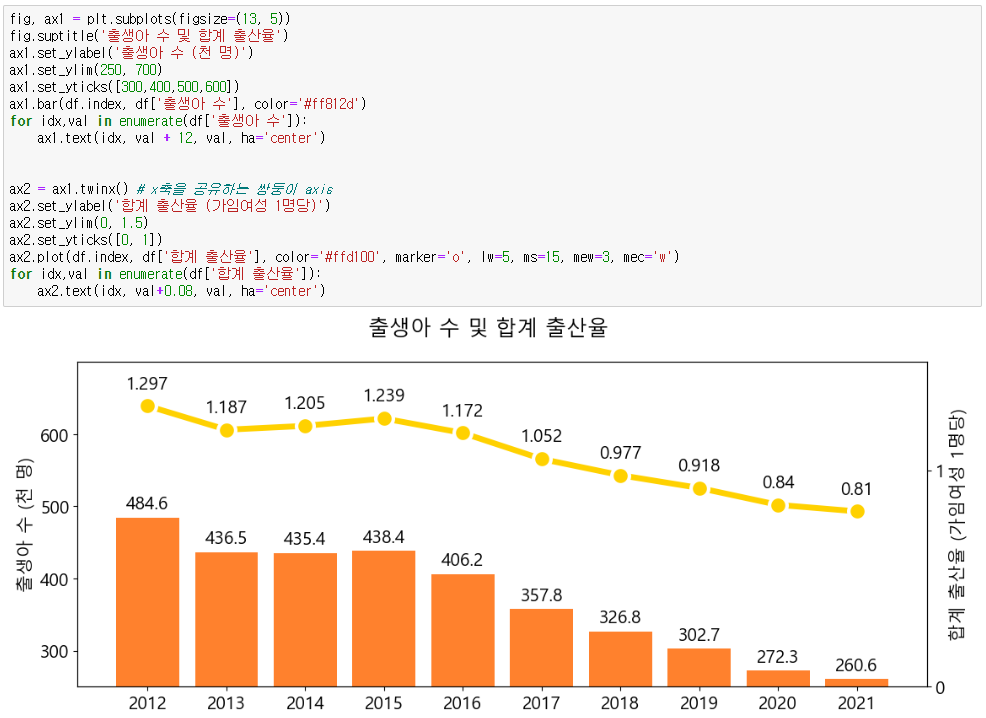
최종 가공을 할 상태이다.
크게 어려운 점은 없다.
다만 text를 입력할때 (x,y) 좌표 위치를 (idx,val + 정수) 로 전달하게 되는데, 이때 입력되는 정수값은 각 y축의 tick 값에 영향을 받는다, 즉 ax1은 100단위로 크기 때문에 12를 더해줘도 위로 많이 안올라가지만, ax2의 경우는 1 단위 이기 때문에 0.08만 입력해줘도 위쪽으로 많이 이동하게 된다.
'개인공부 > python' 카테고리의 다른 글
| 나 혼자 하는 프로젝트 5탄 - OpenCV - 2. 도형 그리기 (0) | 2022.11.23 |
|---|---|
| 나 혼자 하는 프로젝트 5탄 - OpenCV - 1. 이미지&동영상 출력 (1) | 2022.11.22 |
| 나 혼자 하는 프로젝트 4탄 - 데이터 분석 및 시각화 - 인구 피라미드 작성 (0) | 2022.11.17 |
| 나 혼자 하는 프로젝트 4탄 - 데이터 분석 및 시각화 - Matplotlib 퀴즈 (0) | 2022.11.17 |
| 나 혼자 하는 프로젝트 4탄 - 데이터 분석 및 시각화 - Matplotlib 여러 그래프 삽입 (0) | 2022.11.17 |



