어느덧 마무리 퀴즈 시간이다.

퀴즈에 사용할 데이터는 앞서 Pandas 퀴즈 시간에 사용한 영화 데이터와 동일하다.
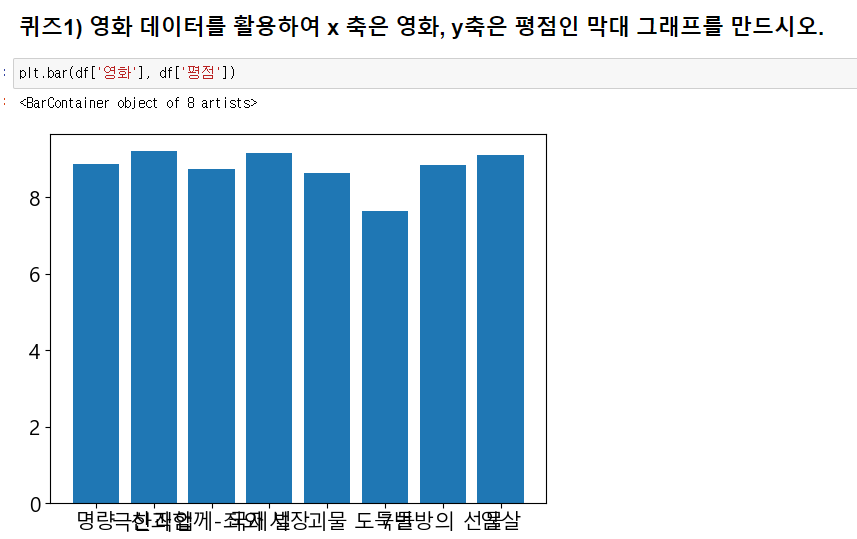
1번 문제는 간단하다. 따로 옵션값을 정의하지 않아 영화 텍스트들이 겹치지만, 일단 해결 완료!

2번 퀴즈 해결을 위해 각 x,y label 값을 설정해 주어야 하고, xticks()의 rotation 값 설정을 통해 텍스트들을 90도 회전시켜 서로 겹치지 않게 정렬해 주었다.
title()로 해당 제목을 붙여주면 2번 문제 해결~
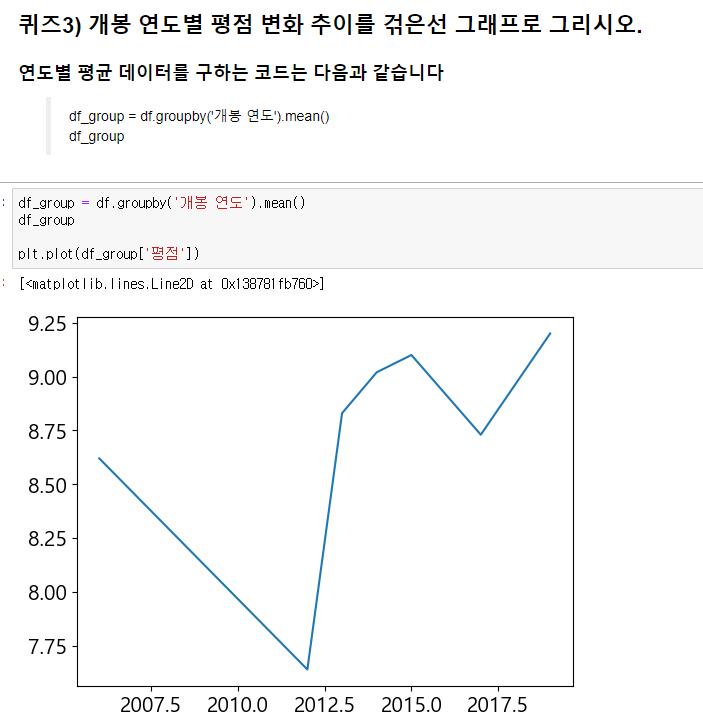
3번 문제는 어렵게 생각하면 해결이 불가능하다.
이미 groupby로 개봉 연도별 그룹화가 실행되었기 때문에 해당 그룹의 ['평점'] 데이터만 넘기면 된다.

index로 해당 데이터의 index값을 확인해보면 '개봉 연도'로 되어 있기 때문에 굳이 x축, y축 데이터를 넘기지 않아도 상관없다. 만약 x축 데이터를 입력하고 싶다면 df_group.index를 전달하면 된다.

4번 문제는 옵션값을 설정하는 것이다.
marker 옵션값을 설정해서 해당 데이터가 존재하는 위치에 o 표시를 해주었고
xticks()에 4개의 년도만 표시되도록 직접 작성해 주었다.
ylim()을 통해 보여지는 값의 범위를 설정해주면, 4번 문제도 해결

5번 문제는 조금 어렵다.
먼저 '평점' column 의 값들을 확인해 보면, float 즉 소수로 작성되어 있다. 이대로는 그룹화를 하더라도 2개의 그룹으로 나눌수 없다. 그래서 함수를 적용해야 하는데, 나는 check_score()라는 함수를 만들어서 이를 해결 하였다.
새로운 column 을 만들어서 check_score()함수가 적용된 새로운 column을 만들어 사용해도 되지만, 나는 바로 groupby()에 해당 함수를 적용시킨 데이터를 할당해 주었다.
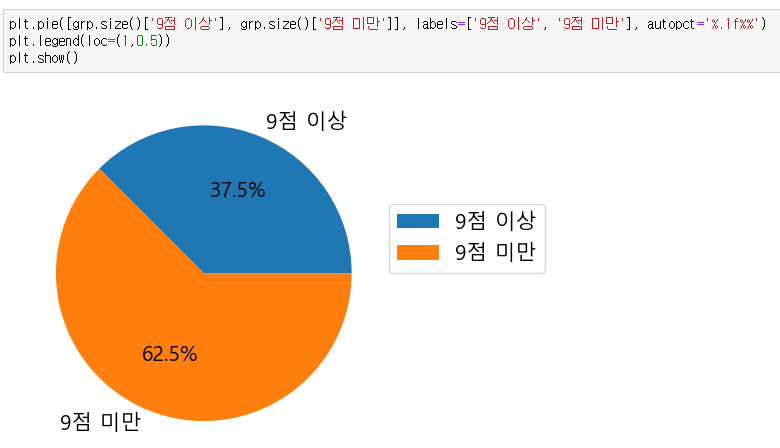
이제 조건에 맞게 원 그래프를 그려주면 된다.
그래프 값으로 사용할 두개의 데이터를 []리스트형으로 전달해 주고, labels= 옵션값도 []리스트로 전달 해주면된다.
autopct=는 소수점 첫 번째 자리까지 이기 때문에 1f 가 된다.
legend() 옵션값으로 loc=()에 위치 좌표를 설정해 주면 해당 퀴즈도 끝이다.

다른 방법으로는 조건에 따른 변수를 생성하여 해당 변수 값을 그래프의 values로 활용하는 방법이다.
이렇게 Matplotlib 의 기초 사용법에 대한 공부한 끝이났다.
'개인공부 > python' 카테고리의 다른 글
| 나 혼자 하는 프로젝트 4탄 - 데이터 분석 및 시각화 - 출생자 수 와 합계출산율 작성 (0) | 2022.11.17 |
|---|---|
| 나 혼자 하는 프로젝트 4탄 - 데이터 분석 및 시각화 - 인구 피라미드 작성 (0) | 2022.11.17 |
| 나 혼자 하는 프로젝트 4탄 - 데이터 분석 및 시각화 - Matplotlib 여러 그래프 삽입 (0) | 2022.11.17 |
| 나 혼자 하는 프로젝트 4탄 - 데이터 분석 및 시각화 - Matplotlib 산점도 (0) | 2022.11.16 |
| 나 혼자 하는 프로젝트 4탄 - 데이터 분석 및 시각화 - Matplotlib 원 그래프 (0) | 2022.11.16 |



