최종적으로 해볼 첫번째 프로젝트 작업은 인구 피라미드를 작성하는 것이다.
먼저 우리나라의 인구 데이터를 가져와서 파일로 저장해 주어야 한다.

다운받은 엑셀 파일은 jupyter notebook의 작업 폴더에 넣어주면, 작업을 시작할 준비가 완료된다.

pandas 를 이용해 해당 파일을 읽어오자.
이때 파일의 1~3행은 불필요한 데이터이기 때문에 skiprows= 를 통해 건너뛰어 주자.
index_col= 을 통해 '행정기관' column을 index로 설정해주고
usecols=로 사용할 columns 를 지정해 주면 된다. 하나하나 입력해도 되고, E:Y 처럼 범위를 지정해 주어도 된다.
이렇게 df_m 에 할당한 DataFrame은 총 17행, 21열의 데이터를 가지게 된다.
화면에 표시하기 위해 head(3)을 통해 3개의 row만 표시해 주었다.
이중에서 필요한 데이터는 '전국' 의 연령별 인구수 이다.

데이터를 사용하기 전에 데이터 가공작업을 해주어야 한다.
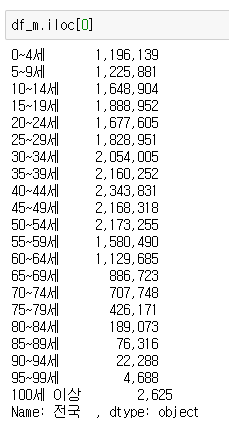
각 인구 수에 쉼표(,)가 존재하며, 해당 값들은 숫자가 아닌 문자형으로 인식된다.

먼저 str.replace()를 통해 해당 쉼표들을 모두 '' 빈 값으로 바꾸어 준다. 또한 astype() 함수를 이요해 해당 값들을 정수형(int)으로 변환해 주면, 남자 인구 데이터는 준비가 되었다.

같은 방법으로 df_w에 여성 인구 데이터를 할당해 주었다.

한가지 특이한 점은 '0~4세.1' 처럼 남성 인구 데이터에 비해 여성 인구 데이터의 columns에는 .1이 붙어 있다. 데이터를 구분하기 위해 자동으로 이름이 바뀌게 되었다.

남성 인구 데이터 columns와 이름이 같아 졌다.
이제 해당 데이터를 토대로 인구 피라미드 그래프를 그려보자.
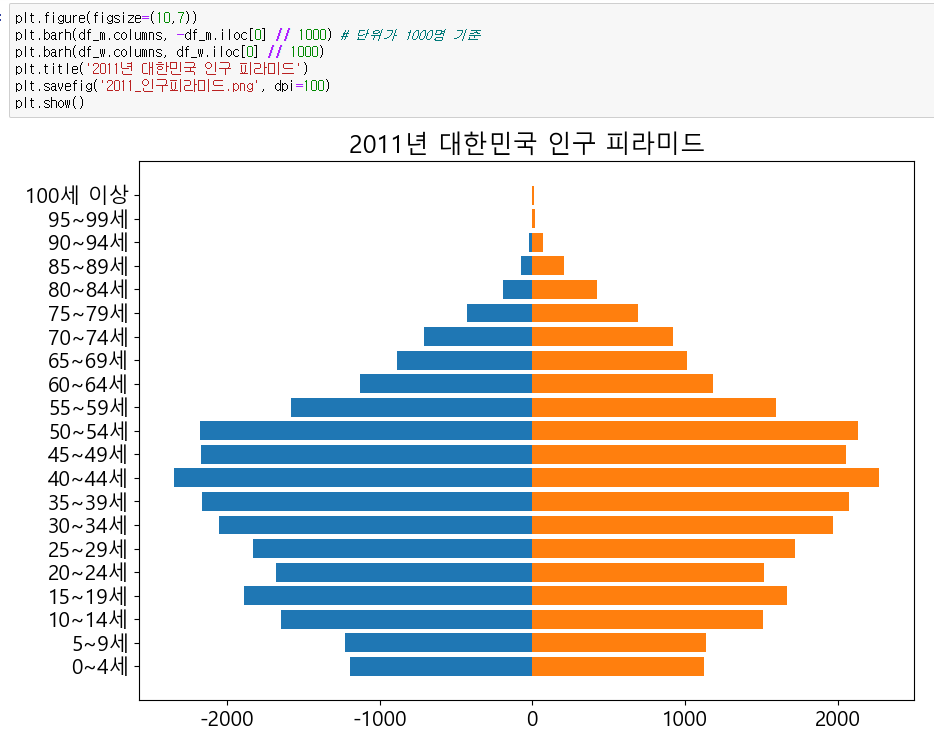
옆으로 뻗는 막대 그래프이기 때문에 barh()를 사용하여 그려준다.
좌우로 그려주는 방법은 생각보다 단순했다, y축 값을 하나는 음수로 전달하면 된다.
이제 2021년 인구 데이터를 다운받아서, 위의 과정을 동일하게 반복하면 된다.


해당 데이터들을 각기 다른 변수명으로 저장하면, 한 그래프에 두 해에 해당하는 수치를 보여줄 수 있다.
이때 alpha값과 막대 색상만 잘 조정하면, 한눈에 어느 연령대별 인구가 감소하고 증가했는지도 알 수 있다.
'개인공부 > python' 카테고리의 다른 글
| 나 혼자 하는 프로젝트 5탄 - OpenCV - 1. 이미지&동영상 출력 (1) | 2022.11.22 |
|---|---|
| 나 혼자 하는 프로젝트 4탄 - 데이터 분석 및 시각화 - 출생자 수 와 합계출산율 작성 (0) | 2022.11.17 |
| 나 혼자 하는 프로젝트 4탄 - 데이터 분석 및 시각화 - Matplotlib 퀴즈 (0) | 2022.11.17 |
| 나 혼자 하는 프로젝트 4탄 - 데이터 분석 및 시각화 - Matplotlib 여러 그래프 삽입 (0) | 2022.11.17 |
| 나 혼자 하는 프로젝트 4탄 - 데이터 분석 및 시각화 - Matplotlib 산점도 (0) | 2022.11.16 |



